Why giving more people access to testing tools creates the illusion of progress while the decisions that matter remain unchanged.
The experimentation industry has settled on a compelling narrative: democratise testing, empower every team to run experiments, and watch innovation flourish. It sounds right. It feels progressive. And for most organisations, it makes things worse.
Not because democratisation is a bad idea. The instinct to spread experimentation beyond a specialist team is sound. The problem is that democratisation addresses the wrong constraint. Most organisations are not held back by too few people running experiments. They are held back by a fundamental disconnect between the evidence they generate and the strategic decisions that evidence should inform.
We call this the Evidence Gap. And democratisation, without the infrastructure to close it, turns a narrow gap into a chasm.
The Promise of Democratisation
“We need to democratise experimentation across the organisation.”
This has become one of the most popular ideas in the experimentation industry. It is promoted by testing tool vendors, championed at conferences, and repeated in countless LinkedIn posts as though it were self-evidently good.
The case for democratisation is straightforward. When experimentation is confined to a small specialist team, it becomes a bottleneck. Product teams wait weeks for test slots. Marketing runs campaigns without validation. Strategic decisions get made on instinct because the experimentation queue is full of tactical optimisations.
Democratisation promises to fix this by giving every team the tools and permission to test. More teams testing means more learning, which means better decisions across the organisation. The logic is clean.
The reality is more complicated. What democratisation actually produces depends entirely on what infrastructure sits beneath it. Without that infrastructure, you do not get distributed learning. You get distributed chaos.
What Actually Happens When You Democratise Without Governance
Picture an organisation that has successfully democratised experimentation. Marketing runs 50 tests a quarter. Product runs 30. Operations runs 20. Each team has adopted its own tools, methodologies, and success criteria.
Meanwhile, the UX research team is conducting 15 studies a quarter, stored in Dovetail. The market research function runs quarterly surveys, reported in PowerPoint decks. The analytics team surfaces behavioural insights in Amplitude dashboards. None of these functions are part of the democratisation conversation, because democratisation is framed as an experimentation initiative. But they are all generating evidence that should inform the same strategic decisions.
On the surface, the experimentation programme looks like progress. Activity dashboards show hundreds of experiments. Leadership presentations feature impressive velocity numbers. The organisation appears to be embracing data-driven decision-making.
Beneath the surface, three structural problems are compounding.
Evidence integrity collapses. When multiple teams run experiments independently, methodology standards diverge. One team uses 90% confidence thresholds while another settles for 80%. Tests collide with each other because nobody has visibility across programmes. Hypotheses are vague or absent entirely. The evidence being generated is unreliable, but nobody knows because there is no quality infrastructure to catch it.
This is a Layer 1 problem in what we call the Decision Intelligence Stack: the organisation cannot trust what it has generated.
Evidence becomes siloed and disposable. Each team stores results in its own system. Marketing uses a spreadsheet. Product uses Notion. Operations tracks everything in Jira tickets. The research team uses Dovetail. Six months later, nobody can find what was learned. Teams unknowingly repeat experiments that were run the previous year. A research study that directly validates or contradicts an experiment’s findings sits in a completely different system, unseen by the experimentation team. Insights from one function that would transform another function’s approach never surface.
This is a Layer 2 problem: the organisation cannot connect what it knows across teams, studies, and time.
Decisions remain unchanged. Despite hundreds of experiments and dozens of research studies, the organisation’s strategic decisions look exactly as they would without any of this activity. Executives see activity reports from the experimentation programme but have no visibility into how those findings connect to the research team’s conclusions. Successful experiments sit unimplemented because no decision protocol existed before the test launched. The board asks about ROI from the combined investment in experimentation and research, and nobody can answer because the two functions have never been connected.
This is a Layer 3 problem: trustworthy, synthesised evidence is not reaching the decisions that matter.
Democratisation created more activity at every layer while solving nothing at any of them. And it did not even address the evidence being generated outside the experimentation programme.

The Centre of Excellence Paradox
Most organisations that recognise the risks of ungoverned democratisation attempt to solve the problem by creating a Centre of Excellence (CoE). On paper, this looks like the answer. The CoE establishes methodology standards, provides training, and acts as a quality checkpoint for experiments across the business.
This is a meaningful step, and it addresses real issues. A well-run CoE can significantly improve evidence integrity by standardising how experiments are designed, executed, and interpreted. It brings consistency where democratisation created fragmentation.
But most CoEs stop at Layer 1. They solve for evidence quality without addressing evidence synthesis or decision influence. The CoE ensures that each individual experiment is well-designed. It rarely ensures that the collective body of evidence is connected, discoverable, and reaching the right decision-makers.
Critically, most experimentation CoEs have no remit over research. The UX research team continues to operate independently, with its own standards, its own repository, and its own reporting line. The CoE governs experiments. Nobody governs the connection between experiments and research. Nobody governs whether either body of evidence reaches strategic decisions.
This creates a paradox: the organisation now produces higher-quality experimental evidence that still sits unused in disconnected systems, alongside higher-quality research evidence that sits in its own disconnected system. Better ingredients, same missing recipe.
The diagnostic question is straightforward: does your CoE cover all three layers, or just the first? And does it cover all types of evidence, or just experiments? Most organisations assume they know the answer. Most are wrong.
In practice, Centres of Excellence also face a structural problem that most organisations never address: they have responsibility without authority.
Responsibility Without Authority
A typical experimentation CoE is staffed by senior practitioners who understand methodology, statistics, and experiment design. They write best practice guides. They create templates. They offer training sessions. They review experiment proposals when asked.
The critical word in that last sentence is “when asked.”
Most CoEs operate as advisory bodies. They can recommend standards but cannot enforce them. They can suggest that a product team redesigns their experiment to avoid a collision, but they cannot prevent the team from launching it anyway. They can flag that a test lacks sufficient sample size, but they have no mechanism to stop it running.
The result is a team that bears the reputational cost of poor experimentation quality while lacking the organisational authority to prevent it. When a badly designed experiment produces a misleading result that leads to a costly implementation failure, it is the CoE that gets questioned. “Isn’t this your job?” The answer, honestly, is: “We told them, but we have no way to enforce our recommendations.”
The Advisory Trap
Over time, this dynamic creates a predictable pattern. The CoE produces increasingly detailed documentation. More playbooks. More guidelines. More training materials. They do this because documentation is the only lever they have.
But documentation without enforcement is just aspiration. A playbook that teams can choose to ignore is not governance. It is a suggestion.
I have seen CoEs with beautifully written 40-page experimentation playbooks that almost nobody follows. The playbook exists. The standards exist. What does not exist is a system that ensures those standards are met before an experiment goes live.
The Evidence Isolation Problem
Of the three layers, evidence synthesis is the one the industry has most thoroughly ignored. Testing platforms help you run experiments. Research tools help you organise qualitative findings. BI dashboards help you visualise data. None of them connect evidence across these sources into cumulative organisational knowledge.
This isolation operates at two levels that compound each other.
Within experimentation, teams are isolated from each other. Marketing’s experiments live in one system, product’s in another, and operations’ in a third. When a product experiment reveals that a navigation change reduces conversion, the marketing team running a campaign test on the same pages has no visibility into that finding. When one team discovers that a pricing hypothesis fails, other teams considering similar pricing tests have no way to learn from it. Evidence stays where it was created, visible only to the team that created it.
Across functions, entire evidence types are isolated from each other. This is the deeper and more damaging problem. The research team conducts a series of user interviews revealing that customers find the checkout flow confusing. The experimentation team, unaware of this research, is running a series of incremental tests on checkout button colours and copy. The analytics team has data showing a significant drop-off at a specific step in the checkout flow. Three functions, three bodies of evidence, all pointing to the same underlying problem, and none of them connected.
In a democratised organisation, this isolation gets worse, not better. Democratisation multiplies the volume of experimental evidence being generated without creating any mechanism to connect it to itself, let alone to research and analytics. More teams producing more evidence across more tools creates an exponentially harder synthesis challenge.
The industry’s response to this has been to build better tools for each silo. Better testing platforms. Better research repositories. Better analytics dashboards. Each tool optimises its own domain while the space between them remains completely unaddressed. A research team using Dovetail and an experimentation team using Optimizely are both well-served within their function. The organisation is poorly served, because the connection between what research discovers and what experimentation validates does not exist as infrastructure.
Any serious approach to democratisation must include a synthesis layer that connects evidence across teams, tools, functions, and time. Without it, each team’s work exists in a vacuum, and the organisation’s collective intelligence remains far less than the sum of its parts.
The Real Problem: Governance is Treated as Optional
Ask most experimentation leaders whether they have governance in place, and they will say yes. What they typically mean is that they have a spreadsheet tracking active experiments, a Jira board for implementation, and Notion pages documenting results.
This is documentation, not governance. The distinction matters.
Documentation records what happened. Governance ensures what should happen. Documentation is a spreadsheet that logs experiment results after the fact. Governance is a quality gate that prevents a poorly designed experiment from launching in the first place. Documentation is a Notion page that stores insights. Governance is a decision protocol that defines, before an experiment begins, who will act on the results and what threshold will trigger action.
Most organisations have assembled what we call a Frankenstack: a collection of general-purpose tools held together by manual effort and good intentions. Airtable for tracking. Jira for implementation. Notion for knowledge. Google Slides for reporting. Each tool does its job adequately. None of them enforce governance. The system works when one person holds it all together manually. It breaks when that person leaves, when the team grows, or when leadership asks a question that requires connecting evidence across tools and time.
Research teams have their own version of this problem. Research repositories like Dovetail and Condens are excellent at organising qualitative findings within the research function. But they have no mechanism to ensure those findings reach the people making strategic decisions, no way to connect research evidence to experimental evidence, and no governance over whether research investments actually influence the outcomes they were commissioned to inform. The research team can tell you what they found. They often cannot tell you what decisions their findings influenced.
Governance should not feel like bureaucracy.
When it works properly, it is invisible. Teams do not feel governed; they feel supported. Quality gates catch problems before they become expensive. Decision protocols eliminate ambiguity about what happens with results. Executive dashboards show strategic impact without requiring practitioners to build bespoke presentations.
Governance is not a separate layer that sits on top of experimentation or research. It is connective tissue that runs through all three layers of the Decision Intelligence Stack. At Layer 1, governance is quality assurance. At Layer 2, governance is knowledge standards. At Layer 3, governance is decision accountability.
Without it, each layer remains aspiration rather than infrastructure.
The Frankenstack Makes It Worse
Compounding the CoE’s authority problem is the technology environment they are trying to govern. Most organisations run experimentation across a disconnected collection of tools that was never designed to work together.
Jira or Linear tracks the work but treats experiments as tasks to be completed rather than knowledge to be created. A ticket is “done” when the code is deployed. In experimentation, deployment is when learning begins.
Airtable or Notion stores the experiment documentation but provides no governance enforcement. There is no quality gate preventing a poorly designed experiment from being marked as complete. Users can modify or delete records with no audit trail. A failed experiment can quietly disappear.
Spreadsheets track results but are prone to version control errors, formula mistakes, and accessibility problems. When the person who built the spreadsheet leaves the organisation, the institutional knowledge goes with them.
Slack or Teams is where the real discussions happen. Why did the test fail? What did we actually learn? Should we iterate or move on? These conversations are ephemeral by nature. The learning that matters most happens in a medium that is designed to disappear.
This is the Frankenstack: a patchwork of generalist tools that creates the illusion of process while preventing true governance. The CoE is trying to enforce standards across tools that were never built to support enforcement.
What Governed Democratisation Actually Looks Like
The goal is not to choose between democratisation and governance. It is to build the infrastructure that makes democratisation work. An organisation with governed democratisation looks fundamentally different from one that simply gave everyone access to testing tools.
At Layer 1: Evidence Integrity. Every experiment, regardless of which team runs it, passes through consistent quality gates. Hypotheses are reviewed before launch. Methodology standards are enforced, not suggested. Collision detection prevents teams from unknowingly interfering with each other’s tests. When results come in, they are interpreted against pre-defined success criteria rather than post-hoc rationalisations. Research studies are similarly governed: commissioned against strategic priorities, designed with clear methodological standards, and conclusions verified before they enter the organisation’s evidence base.
At Layer 2: Evidence Synthesis. Insights from every team, every experiment, and every research study flow into a connected knowledge system. Past evidence is discoverable. Patterns across studies surface automatically. Teams build on what the organisation already knows rather than starting from scratch each time. Research findings inform experiment design. Experiment results validate or challenge research conclusions. A product team designing a test can see what the UX research team already learned about the same customer behaviour. Evidence compounds rather than decays, across functions and across time.
At Layer 3: Decision Influence. Before any experiment or research study launches, a decision protocol defines who will use the results and what action they will take. Executive dashboards show which strategic decisions were informed by evidence, not just how many tests were run or how many studies were completed. Implementation rates are tracked. Researchers know when their work influenced a decision. Experimentation teams know when their results were acted on. The gap between claimed evidence value and actual business impact is visible and accountable.
This is the complete Decision Intelligence Stack. Each layer builds on the one beneath it. Trustworthy evidence becomes more valuable when it is connected, and connected evidence becomes strategically powerful when it reaches the right decisions.
The Five Requirements for Governed Democratisation
Organisations that want to democratise experimentation without falling into the trap need five things in place.
Methodology enforcement, not just methodology guidelines. Guidelines are suggestions. Enforcement is infrastructure. The difference is whether a team can launch an experiment with a vague hypothesis and no success metric. In a governed system, they cannot, because the quality gate requires it. This applies equally to research: a study commissioned without a clear business question and decision owner is unlikely to influence anything, regardless of how well it is conducted.
Cross-team visibility and collision prevention. When multiple teams experiment on the same product surface, collisions are inevitable without infrastructure to prevent them. A marketing team’s homepage test and a product team’s navigation experiment can invalidate each other’s results without either team knowing. Governed democratisation requires a single source of truth for what is running, where, and when.
Evidence synthesis across teams, tools, functions, and time. The most valuable insight in any organisation is often the one that connects findings from different teams examining the same problem from different angles. A research study that identifies a customer pain point becomes dramatically more valuable when connected to an experiment that tests a solution to that same pain point. Without synthesis infrastructure, this connection happens only by accident, in a corridor conversation or a chance meeting. Governed democratisation makes this connection systematic rather than accidental.
Decision protocols defined before evidence generation begins. An experiment without a decision protocol is an academic exercise. A research study without a decision owner is an expensive report. Before any test begins or any study is commissioned, someone should have defined: what decision does this inform, who is the decision-maker, and at what threshold will we act? This transforms both experimentation and research from activities that generate interesting data into processes that drive business outcomes.
Executive dashboards that show decision influence, not activity. The moment leadership evaluates experimentation by test count or research by study volume, both programmes are incentivised to optimise for activity rather than impact. Executive dashboards should answer one question: how is our evidence investment influencing strategic decisions? This means showing implementation rates, decision influence metrics, and business outcomes rather than velocity charts and research output summaries.
Democratisation is Not the Starting Point
The experimentation industry has spent years advocating for democratisation as the path to maturity. The logic seems sound: more people testing means more learning means better decisions.
The evidence suggests otherwise. Organisations with the strongest evidence-to-decision infrastructure are not distinguished by how many people can run tests. They are distinguished by the infrastructure connecting experiments, research, and analytics to strategic decisions. They have governance that ensures evidence quality across functions. They have synthesis that connects evidence across teams and evidence types. They have decision protocols that ensure evidence reaches the people who need it.
Democratisation is not the starting point. It is the scaling mechanism that works once the infrastructure is in place. Without that infrastructure, democratisation simply distributes the problem.
The goal was never to run more experiments. The goal was to make better decisions.
The Sequence That Works
Organisations that successfully govern democratised experimentation tend to follow a consistent sequence.
Start by diagnosing the gap. Before investing in any solution, understand where your Evidence Gap is widest. Is the primary problem evidence integrity (Layer 1), evidence synthesis (Layer 2), or decision influence (Layer 3)? Most organisations assume they know, and most are wrong. A diagnostic that assesses all three layers across both experimentation and research, typically within two weeks, gives you a clear picture of where infrastructure is needed most.
Address the most acute layer first. If evidence integrity is the primary gap, governance infrastructure closes it. If evidence synthesis is the bottleneck, connecting what you already know across teams, functions, and time unlocks compounding value from existing investments. If evidence is trustworthy and connected but not reaching decision-makers, decision protocols and executive dashboards close the final gap.
Expand as the programme matures. The three layers build on each other. Trustworthy evidence (Layer 1) becomes more valuable when it is connected (Layer 2), and connected evidence becomes strategically powerful when it reaches the right decisions (Layer 3). Organisations that start with one layer naturally expand to the others as they see the compounding value.
This is not a multi-year transformation programme. Each layer delivers standalone value. But the compound effect of all three working together is what separates organisations that run experiments from organisations that make better decisions.
How Efestra Closes the Evidence Gap
I started building what became Efestra in 2015, when the problem looked simpler than it turned out to be. Back then, I was working with experimentation teams across Europe and seeing the same thing everywhere: brilliant specialists running sophisticated tests with no central record of what they had learned. Experiments tracked in spreadsheets, if at all. Insights that vanished when a team member left. One global retailer had unknowingly run the same checkout test sixteen times across different teams.
The first version of the platform solved that. It gave teams a central place to document experiments and their outcomes. For the first time, experimentation became visible within these organisations.
But visibility was not enough. Year after year, I kept seeing the same pattern: teams documented more, ran more tests, produced more evidence, and yet the strategic decisions being made above them looked no different. The evidence was not reaching the people who needed it. That realisation led to a shift from experimentation management to experimentation governance, and to what we called the Trust Gap: the disconnect between promising test results and leadership confidence to act on them.
Governance helped close the Trust Gap at Layer 1. But working with hundreds of programmes over nearly a decade made something else clear. The problem was not confined to experimentation. Research teams were generating their own body of evidence in complete isolation. Analytics teams were surfacing patterns that never informed test design. And none of this evidence, whether from experiments, research, or analytics, was systematically reaching strategic decisions. The gap was not just about trust in individual experiments. It was about the entire infrastructure connecting evidence to decisions.
That is what led to the Decision Intelligence Stack and the three-layer framework described in this article. It is not a theoretical model. It is the pattern that emerged from watching hundreds of organisations struggle with the same structural problem, regardless of how many tests they ran or how good their research was.
Today, Efestra builds decision intelligence infrastructure across all three layers. Rather than a single platform that requires full commitment, we offer distinct entry points that address the specific layer where your gap is widest.

Observatory diagnoses the Evidence Gap across all three layers. It connects read-only to your existing tools, whether that is Airtable, Jira, ClickUp, or Asana, analyses your historical data, and delivers a report that quantifies where evidence integrity, synthesis, and decision influence are breaking down. For organisations unsure where to start, Observatory provides the answer within two weeks. For those who want continuous visibility without changing their existing workflow, Observatory Ongoing provides a permanent governance layer that flags issues in real time.
Observatory sits above your existing tools without requiring any workflow change. Prism and Flywheel replace the Frankenstack: instead of stitching together Airtable, Jira, Notion, and Google Slides to approximate governance and synthesis, they provide purpose-built infrastructure for evidence integrity, synthesis, and decision influence.
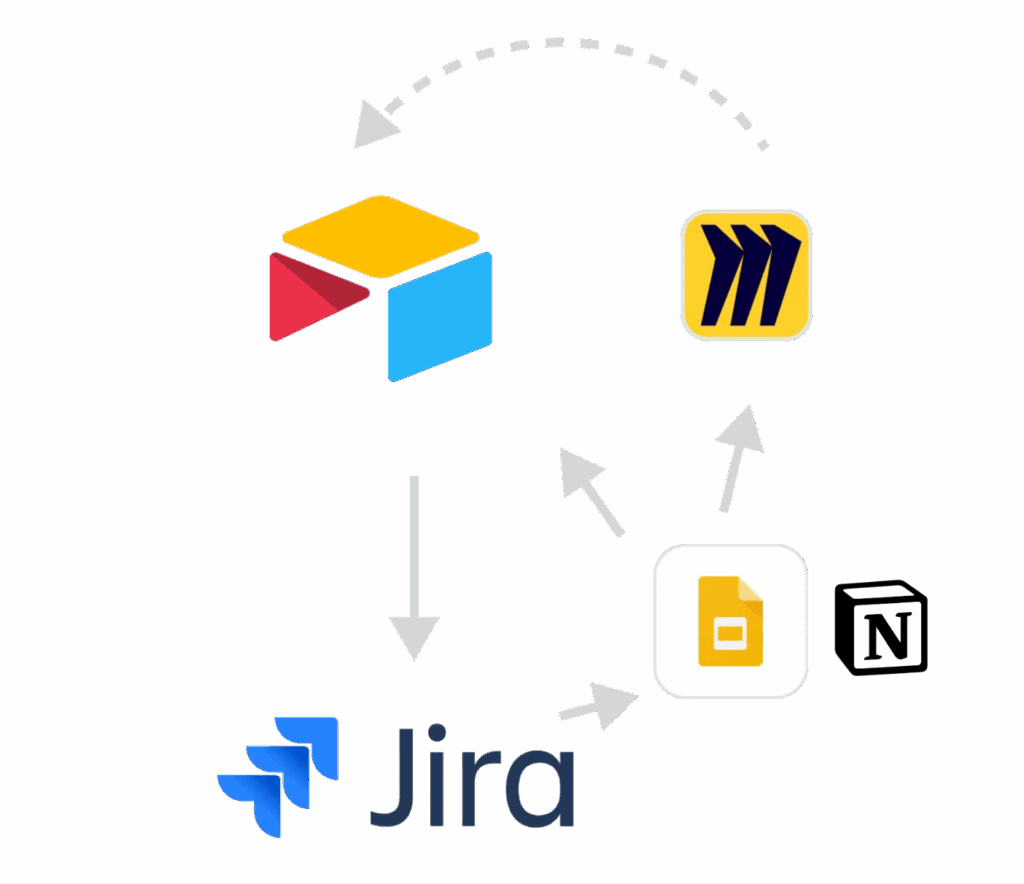
Prism addresses Layer 2: evidence synthesis. It connects evidence from experiments, research studies, and analytics across teams and time periods. AI-assisted synthesis surfaces patterns that would take weeks to identify manually, while researchers and analysts retain control of verification and interpretation. For organisations where research and experimentation operate in silos, Prism is the layer that connects them. Research teams use Prism to prove the impact of their work by tracking when synthesised evidence influences a decision. Experimentation teams use it to build on what the organisation already knows rather than starting from scratch.
Flywheel addresses Layers 1 and 3 with the complete governance infrastructure. Quality gates, collision detection, approval workflows, and methodology standards ensure that every experiment produces trustworthy evidence. Decision protocols, executive dashboards, and implementation tracking ensure that evidence reaches the strategic decisions it should inform.
There is a version of the Evidence Gap that the Decision Intelligence Stack does not fully address, and it took a specific pattern of conversations to see it clearly.
The organisations described so far have experimentation programmes. They generate evidence. The problem is governance: quality is inconsistent, insights leak, decisions are not connected to evidence. The fix is infrastructure at Layer 1, Layer 2, or Layer 3 depending on where the gap is widest.
But a growing number of organisations are reaching out with a different problem. They are not running a flawed programme. They are not running one at all. Product managers are making decisions based on intuition and assumption. The team knows they should be testing, but there is no methodology, no infrastructure, and no clear starting point. The gap is not about evidence quality. It is about whether evidence is being generated at all.
Buying a testing tool does not solve this. Amplitude and Optimizely handle execution. They do not tell a product manager whether the experiment they are about to run is worth running. A consultant solves the knowledge problem for as long as they are in the room. Playbooks and frameworks from Speero or CXL give teams a map, but not the infrastructure to follow it consistently over time.
This is what led to Launchpad, Efestra’s entry point for teams at near-zero maturity.
The centrepiece is Mosaic Guide, an AI experiment planner that takes a rough idea in plain language and shapes it into a structured experiment plan with governance built in invisibly. A product manager types something like “I want to try adding social proof to the pricing page.” Mosaic Guide analyses the idea, surfaces what is missing, generates a properly structured hypothesis, flags any collisions with experiments already running, and produces a plan card ready to take into whatever testing tool the team uses.
The learning happens by seeing the difference between what the PM wrote and what a good experiment plan looks like. Governance is not a checklist to complete. It becomes the default.
Launchpad sits at Layer 1 of the Decision Intelligence Stack, but in guided form rather than enforced form. The boundary between the two matters: Launchpad suggests, nudges, and surfaces. Foundation enforces. Teams that outgrow Launchpad, where the decision rate falls below fifty per cent or where coordination across multiple squads becomes the constraint, have a natural path to Foundation. The product surfaces that gap rather than waiting for a sales conversation to identify it.
The table below illustrates where the gap sits. Every category of tool in the current ecosystem covers a fragment of the Decision Intelligence Stack. None of them cover it all.
| Category | Layer 1: Evidence Integrity | Layer 2: Evidence Synthesis | Layer 3: Decision Influence | Governance |
| Testing platforms (Optimizely, VWO, AB Tasty, Statsig) | Partial | None | None | None |
| Research tools (Dovetail, EnjoyHQ, Condens) | None | Partial (Research only) | None | None |
| BI tools (Tableau, Looker, Amplitude) | None | None | Partial (dashboards) | None |
| Feature flags | Partial | None | None | None |
| General-purpose tools (Jira, Airtable, Confluence, spreadsheets) | None | Partial (manual) | Partial (dashboards) | None (documentation only) |
| Agencies and consultancies | Partial (per engagement) | Partial (per engagement) | None | None |
| Efestra | Full | Full | Full | Full |
These tools are valuable for what they do but they are components in a stack that is missing the connecting layer. The distinction is worth stating plainly. Tools let you run tests. Efestra makes sure the tests are worth running.
If you are not sure where your Evidence Gap is widest, start with an Observatory diagnostic.






