
You’ve built the culture. You’ve implemented the rituals. Your teams celebrate wins, share learnings, and everyone talks about being “data-driven.” Yet your experimentation program is stuck in neutral.
Sound familiar?
The uncomfortable truth is that most experimentation programs plateau not because of culture, but because of a fundamental gap between good intentions and operational reality. While center of excellence teams and program managers excel at evangelizing experimentation, they lack the tools to enforce the quality standards that transform random testing into strategic growth.
The Scaling Paradox: More Tests, Less Impact
Research from leading experimentation platforms reveals a troubling pattern: as organizations scale their testing velocity, the marginal value of experiments often decreases. Companies running hundreds of concurrent experiments report:
- Quality degradation as attention becomes divided across too many tests
- Increasing operational overhead that grows super-linearly with test volume
- Difficulty maintaining audit trails and oversight across distributed teams
- Inability to enforce consistent hypothesis quality and statistical rigor
The result? Organizations become victims of their own success. They’re running more tests than ever, but leadership asks the inevitable question: “Why isn’t this moving our bottom line?”
The Center of Excellence Paradox
Experimentation specialists within Centers of Excellence excel at what they’re hired to do: training, evangelization, and building rituals around testing. They create comprehensive playbooks, run workshops, lunch & learns and champion data-driven decision making. But here’s the uncomfortable truth: monitoring experimentation adoption, let alone quality at scale, is an impossible job for even the most dedicated teams.
These specialists face an insurmountable challenge. They’re expected to:
- Train hundreds of team members across different functions
- Maintain quality standards across dozens or hundreds of concurrent experiments
- Review every hypothesis, validate test setups, and ensure statistical rigor
- Track adoption metrics and program health
- Continue evangelizing and building culture
The result? An awful amount of trust is given without guardrails in place.
Centers of Excellence become cheerleaders rather than quality enforcers, hoping that good intentions translate into good experiments.
The Ritual Theater Problem
Organizations develop an over-reliance on rituals and meetings to surface insights and demonstrate best practices. Weekly experiment reviews, monthly learning sessions, quarterly retrospectives. While these ceremonies have value, they create a false sense of control.
The reality is that:
- Only the “success stories” make it to these meetings
- Failed or inconclusive tests are quietly buried
- Teams learn to game the system, presenting experiments in the best possible light
- The sheer volume of experiments makes comprehensive review impossible
- Insights shared in meetings rarely translate into systematic improvements
These rituals become performance theater, where everyone plays their part but the underlying quality issues remain unaddressed.
Where Playbooks Break Down

Traditional experimentation playbooks fail at scale for three critical reasons:
1. The Enforcement Gap
No matter how customized or flexible a playbook might be, if it’s not built into the workflow, it’s not enforceable. Centers of Excellence can create the most comprehensive guidelines, but they lack the mechanisms to ensure teams actually follow them.
Without automated enforcement:
- Teams skip steps when under pressure
- Quality standards become “nice-to-haves” rather than requirements
- Bad practices proliferate faster than good ones
- The burden of enforcement falls on already overwhelmed specialists
Reality: Playbooks become aspirational documents that gather digital dust while teams cherry-pick what’s convenient.
2. The Bandwidth Crisis
Centers of Excellence operate under a fundamental resource constraint. A typical team of 3-5 experimentation specialists cannot possibly monitor hundreds of experiments across dozens of teams. The math simply doesn’t work.
Consider the reality:
- Each experiment requires review at multiple stages (hypothesis, setup, analysis)
- Quality assessment takes time and expertise
- Teams need ongoing coaching and support
- New team members require training
- Documentation and playbook updates demand attention
The specialists who should be ensuring quality are instead stuck in an endless cycle of training and evangelization, hoping their teachings stick.
3. The Tool Fragmentation Problem
Most organizations cobble together experimentation programs using:
- Spreadsheets for tracking ideas and results
- Generic project management tools for workflow
- Separate analytics platforms for analysis
- Communication tools for sharing learnings
This fragmentation makes it impossible to enforce standards or maintain visibility across the entire experimentation lifecycle.
Reality: Critical information lives in silos, making it impossible to identify patterns, prevent duplicate tests, or build on previous learnings systematically.
The Operational Intelligence Solution
The path forward isn’t abandoning playbooks or doubling down on culture. It’s operationalizing your experimentation standards through intelligent automation and integrated workflows.
Successful scaling requires:
Automated Quality Enforcement
- Pre-flight checks that validate hypothesis quality before tests launch
- Automated sample size calculations and power analysis
- Real-time monitoring for data integrity and statistical validity
- Alerts for test interference and segment overlap
Integrated Workflow Management
- Centralized experiment repository with full lifecycle tracking
- Role-based workflows that enforce review and approval processes
- Automated documentation of changes and decision rationale
- Built-in templates that embed best practices into daily work
Continuous Program Intelligence
- Real-time dashboards showing program health metrics
- Automated identification of low-quality experiments
- Team performance analytics to identify training needs
- ROI tracking that connects experiments to business outcomes
Efestra: Where Playbooks Become Living Systems
Efestra transforms static playbooks into dynamic, enforceable systems that scale with your organization. Instead of hoping teams follow best practices, Efestra ensures they do, while giving Centers of Excellence the leverage they need to maintain quality at scale.
How Efestra Empowers Centers of Excellence:
Automated Enforcement That Scales Your playbook becomes the workflow. Teams can’t skip critical steps or ignore quality standards because the system guides them through proven processes. Centers of Excellence set the rules once, and Efestra enforces them across every experiment.
Bandwidth Multiplication Instead of manually reviewing every experiment, specialists focus on:
- Setting and refining quality standards
- Analyzing program-level trends and patterns
- Coaching teams flagged by automated quality checks
- Continuous improvement of the experimentation framework
Efestra handles the routine enforcement, freeing specialists to do what they do best: drive strategic improvements.
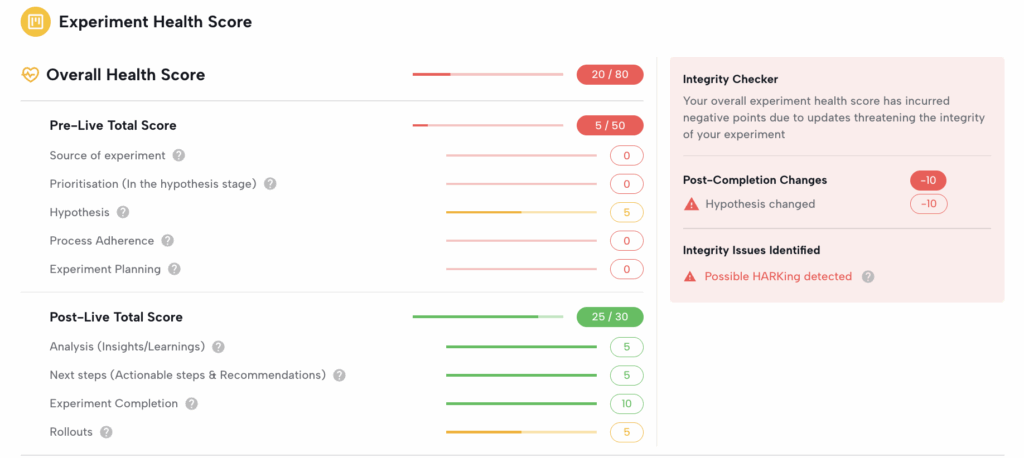
Real-Time Quality Monitoring
- Automated quality scores for every experiment
- Alerts for experiments that deviate from standards
- Dashboard views of program health across all teams
- Proactive identification of teams needing support
Centers of Excellence gain unprecedented visibility without the impossible burden of manual review.
Beyond Ritual to Real Impact Replace performance theater with genuine insights:
- Automated insight capture from every experiment
- AI-powered pattern recognition across all tests
- Systematic knowledge building that compounds over time
- Data-driven identification of what actually drives impact
Centers of Excellence shift from hoping good practices spread to knowing they’re being followed.
Intelligent Knowledge Management Unlike scattered documentation and meeting notes, Efestra creates a searchable, interconnected knowledge base where:
- Every experiment builds on previous learnings
- AI surfaces relevant past tests automatically
- Teams avoid duplicate efforts and conflicting tests
- Cumulative learnings compound into competitive advantage
The Bottom Line: From Trust to Verification
Great Centers of Excellence shouldn’t have to choose between evangelization and enforcement. They shouldn’t have to trust that teams are following best practices when they could know they are.
Efestra gives experimentation specialists the leverage they desperately need. It’s the difference between:
- Hoping teams attend training vs. embedding training in the workflow
- Trusting quality standards are met vs. automatically enforcing them
- Manually reviewing a sample vs. monitoring everything in real-time
- Sharing insights in meetings vs. systematically building organizational knowledge
Centers of Excellence can finally focus on what matters most: driving strategic experimentation initiatives that deliver measurable business impact.
Ready to give your Center of Excellence the tools they need to succeed at scale? Discover how leading organizations use Efestra to transform their experimentation programs from well-intentioned efforts into systematic growth engines.
Schedule a demo to see how Efestra can operationalize your experimentation playbook and unlock the true potential of your testing program.






